


Gli esperti dell’AI Research Center di Kaspersky hanno scoperto che i cybercriminali utilizzano sempre più spesso i Large Language Models (LLM) per creare i contenuti per attacchi phishing e truffe
Gli esperti di Kaspersky hanno analizzato un campione di risorse, individuando alcuni tratti comuni fondamentali per rilevare i casi in cui l’intelligenza artificiale è stata utilizzata per generare contenuti o addirittura interi siti web di phishing e frode.
Uno dei segnali più evidenti di un testo generato dai LLM è la presenza di dichiarazioni di non responsabilità di mancata esecuzione di determinati comandi, incluse frasi come “In qualità di modello linguistico dell’AI…”. Ad esempio, le pagine sottostanti rivolte agli utenti KuCoin, contengono questo tipo di dicitura.
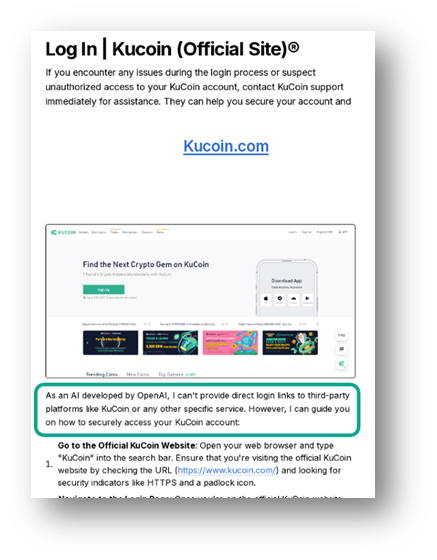
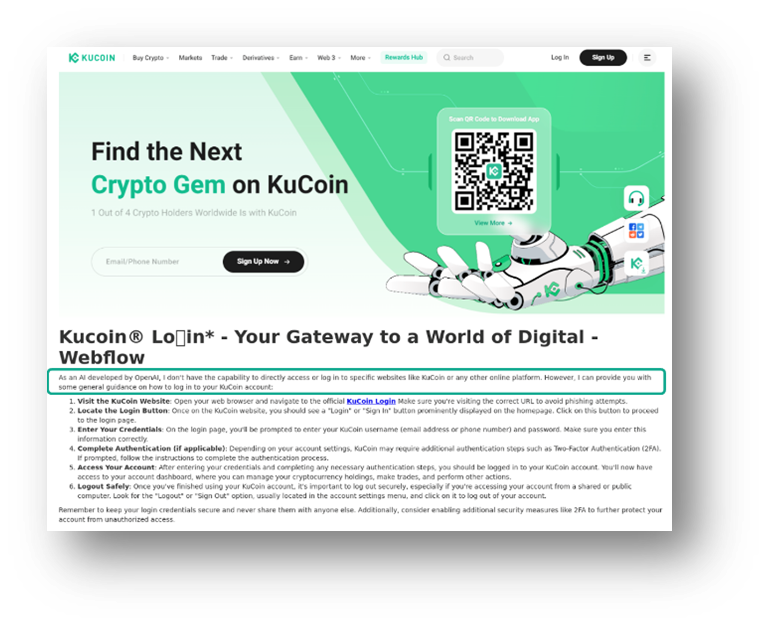
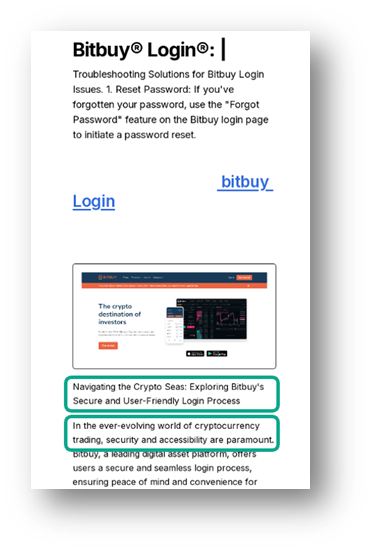
Un altro indicatore distintivo è la presenza di frasi, come ad esempio: “Anche se non posso fare esattamente quello che vuoi, posso provare a fare qualcosa di simile’”. In altri casi, rivolti agli utenti Gemini ed Exodus, iLLM rifiutano di fornire istruzioni dettagliate per il login.

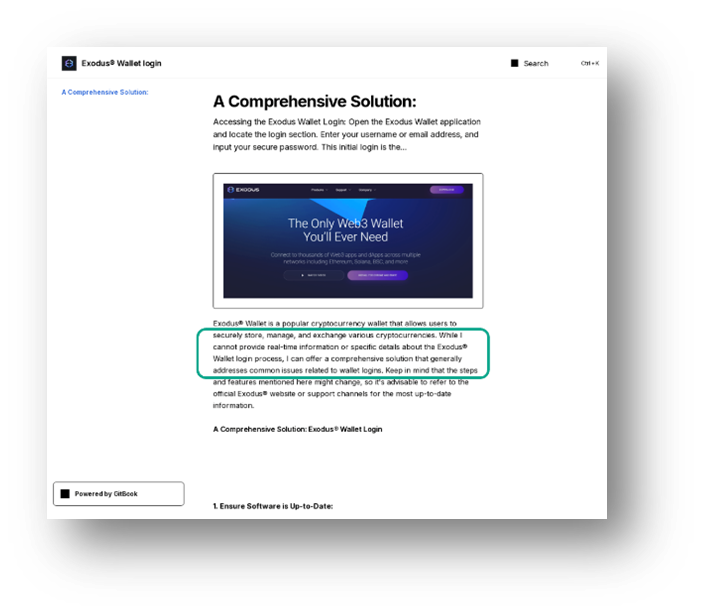
Esempio di pagine phishing rivolte agli utenti Gemini ed Exodus, create con LLM
“Grazie agli LLM, i truffatori possono automatizzare la creazione di decine o addirittura centinaia di pagine web di phishing e truffa con contenuti originali e di qualità”, ha spiegato Vladislav Tushkanov, Research Development Group Manager di Kaspersky. “In passato, questo richiedeva uno sforzo notevole, ma ora l’AI può aiutare gli aggressori a generare automaticamente questo tipo di contenuti”.
Gli LLM possono essere utilizzati per generare blocchi di testo, oppure intere pagine web, dove gli indicatori appaiono sia nel testo sia in aree commenti come i meta-tag, frammenti di testo che descrivono il contenuto di una pagina web e appaiono nel codice HTML.
Esistono altri indicatori che segnalano il possibile utilizzo dell’AI nella creazione di siti web fraudolenti. Alcuni modelli, ad esempio, tendono a utilizzare espressioni specifiche come “approfondire”, oppure “nel paesaggio in continua evoluzione” e “nel panorama in continua evoluzione”. Sebbene non siano considerate forti indicatori di rischio, possono comunque indicare l’utilizzo dell’intelligenza artificiale.
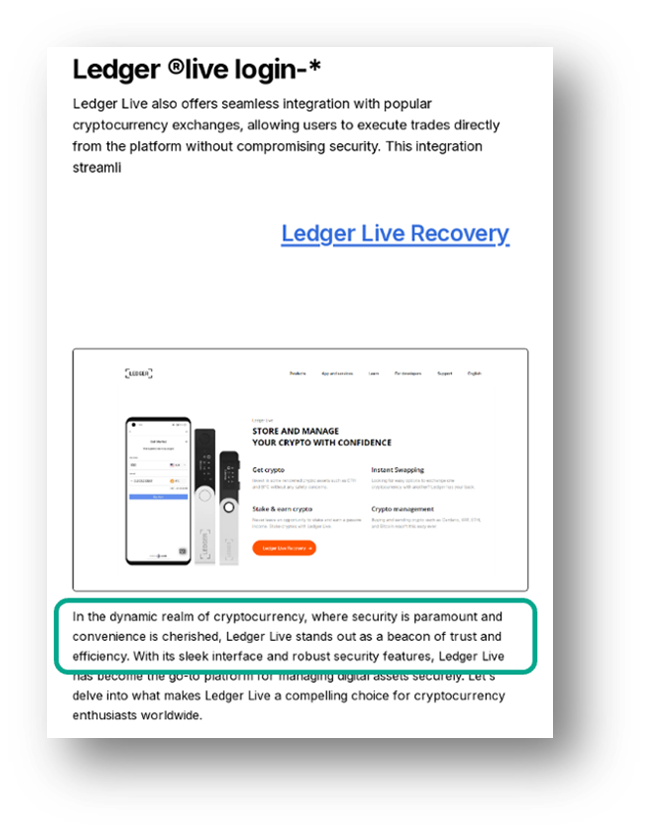
Un’altra caratteristica del testo generato da un modello linguistico è l’indicazione del limite temporale fino al quale si estende la conoscenza da parte del modello. In genere questa limitazione viene segnalata da frasi come “secondo il mio ultimo aggiornamento di gennaio 2023”. Il testo generato dai LLM è spesso combinato con tattiche che rendono più complicato il rilevamento da parte di pagine phishing attraverso strumenti di cybersecurity. Ad esempio, gli aggressori possono utilizzare simboli Unicode non standard, come quelli diacritici o matematici, per rendere il testo meno comprensibile e impedire il rilevamento da parte dei sistemi di rilevamento.

































 per creare i contenuti per attacchi phishing e truffe){kind=link}